Wie man einen OpenMP Workerthread in Qt umsetzt und mit einem Progressdialog im Qt GUI Thread kombiniert
In diesem Artikel wird beschrieben, wie man in einem Qt Programm längere, rechenintensive Berechnungen in einen Workerthread auslagert und diesen mit einem QProgressDialog im GUI Thread kommunizieren lässt. Außerdem wird gezeigt, wie man Fortschrittsinformationen aus einem mit OpenMP parallelisierten Teil nach außen leitet.
Ein komplettes Beispiel gibt es als Quelltext-Archiv: OpenMPAndQtProgressDialog-Example.7z
Allgemeines
Qt bietet mit der Klasse QThread eine Kapselung der plattformspezifischen Threads an.
Grundlegendes zur Verwendung der QThread Klasse wird in Zwei Methoden, um einen Qt Workerthread zu verwenden beschrieben.
Häufig ist es aber bei numerischen Berechnungen auch innerhalb von Qt Programmen sinnvoll, OpenMP für die Parallelisierung zu verwenden. In diesem Artikel geht es nun darum, wie man von OpenMP-parallelisierten Workerthreads aus mit dem GUI Thread kommuniziert.
OpenMP in pro-Dateien anschalten
Damit man OpenMP in Qt-Programmen benutzen kann, fügt man folgenden Code in die pro-Datei ein:
message(Setting up OpenMP support)
# setup linker and compiler flags
CONFIG(debug, debug|release) {
QMAKE_CFLAGS = -fopenmp -fPIC -march=core-avx-i -mtune=core-avx-i
} else {
QMAKE_CFLAGS = -fopenmp -fPIC -O3 -march=core-avx-i -mtune=core-avx-i
}
QMAKE_LFLAGS = $$QMAKE_CFLAGS
QMAKE_CXXFLAGS = $$QMAKE_CFLAGS
WorkerThread mit OpenMP-Parallelisierter Schleife
Analog zum WorkerThread Beispiel im oben verlinkten Post wird ein WorkerThread erstellt mit folgendem Code:
WorkerThread.h
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#ifndef WORKERTHREAD_H
#define WORKERTHREAD_H
#include <QThread>
class WorkerThread : public QThread {
Q_OBJECT
public:
// if set to true by master thread, the worker should stop its work fast
bool m_abort = false;
protected:
// QThread interface
void run() override;
signals:
// emitted repeatedly as work progresses
void progress(QString text, int value, int maxValues);
};
#endif // WORKERTHREAD_H
Und die Implementierung:
WorkerThread.cpp
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
#include "WorkerThread.h"
#include <omp.h>
#include <cmath>
#include <QElapsedTimer>
void WorkerThread::run() {
const int maxCycles = 100000;
QElapsedTimer timer; // timer for master thread
timer.start();
// start work in parallel region
#pragma omp parallel for schedule(static,100)
for (int i=0; i<maxCycles; ++i) {
// fast forwards if we have canceled the run
if (m_abort)
continue;
if (omp_get_thread_num() == 0) {
if (timer.elapsed() > 100) {
emit progress(tr("Looping..."), i, maxCycles);
timer.restart();
}
}
// do some meaningless work
double x = 0;
for (int j=0; j<100000; ++j)
x += std::sin(std::sqrt(j));
} // end parallel for
}
Der Workerthread durchläuft einfach eine Schleife mit maxCycles Durchläufen und berechnet darin ein paar Wurzeln und Sinuswerte, um etwas Last zu generieren.
Die Schleifendurchläufe sind allesamt unabhängig, weswegen die Schleife mit OpenMP direkt parallelisiert werden kann:
1
2
3
4
#pragma omp parallel for
for (int i=0; i<maxCycles; ++i) {
// ...
}
Fortschrittsmeldung zur GUI
Der Workerthread soll nun seinen Fortschritt an die GUI melden. Damit man unabhängig von der CPU Leistung hinreichend häufig ein Update für den Progressdialog schickt, emittiert man sinnvollerweise in regelmäßigen Intervallen ein Signal.
1
2
3
4
5
6
7
8
9
10
11
12
QElapsedTimer timer; // timer for master thread
timer.start();
// ...
if (omp_get_thread_num() == 0) {
if (timer.elapsed() > 100) {
emit progress(tr("Looping..."), i, maxCycles);
timer.restart();
}
}
}
Wichtig ist, dass das timer-Objekt nur vom Masterthread verändert wird (durch Aufruf von
timer.restart()) und dass dasemitauch nur vom MasterThread ausgeführt wird. Deshalb wird dieser Block mit einemif (omp_get_thread_num() == 0)geschützt (eine Verwendung von#pragma omp masterist im Schleifenkontext nicht möglich).
Das Progress-Signal ist wie folgt deklariert:
1
2
3
signals:
// emitted repeatedly as work progresses
void progress(QString text, int value, int maxValues);
Wenn man den Code nun so laufen lässt, so bewegt sich der Balken nur sehr langsam und beim Erreichen von ca. 10% (auf meinem Rechner mit 12 CPUs) ist die Schleife dann auch schon fertig. Das liegt daran, dass OpenMP die Arbeitslast der Schleife standardmäßig gleichverteilt auf alle Prozesse legt. Hätte man 10 Threads, dann würde der Masterthread (höchstwahrscheinlich) nur die ersten 10% der Indexe bearbeiten und entsprechend auch nur deren Nummern via im progress-Signal emittieren.
Besser ist es daher, die for-loop mit einem schedule-clause zu versehen:
1
2
3
4
#pragma omp parallel for schedule(static,100)
for (int i=0; i<maxCycles; ++i) {
// ...
}
So bekommt der Masterthread z.B. die Chunks 0..99, 1200..1299, 2400..2499,…. und der Progressbalken wächst fröhlich vor sich hin bis 100%.
Die Verwendung einer
schedule-clause ist auch dann immer sinnvoll, wenn der zeitliche Aufwand für das Bearbeiten der Schleifenindexe nicht immer identisch ist. Sonst würde z.B. ein Thread an seinem Chunk mit den zeitaufwändigen Indexen länger werkeln, während alle anderen Däumchen drehen und warten. Beischedule(static,100)bekommt jeder Thread nur einen Teil der Daten und holt sich nach Abarbeitungsende einfach den nächsten Batzen. Es gibt zwar einen Overhead für die dafür benötigte Synchronisation, aber solange der Arbeitsaufwand für einen Schleifenindex hinreichend groß ist, fällt das nicht weiter ins Gewicht.
Wenn man den Code nun laufen lässt, sieht man eine nahezu perfekte Parallelisierung (100% Last auf allen Kernen, wie man im btop-screenshot unten gut sehen kann) und die Ausführungszeit reduziert sich entsprechend:
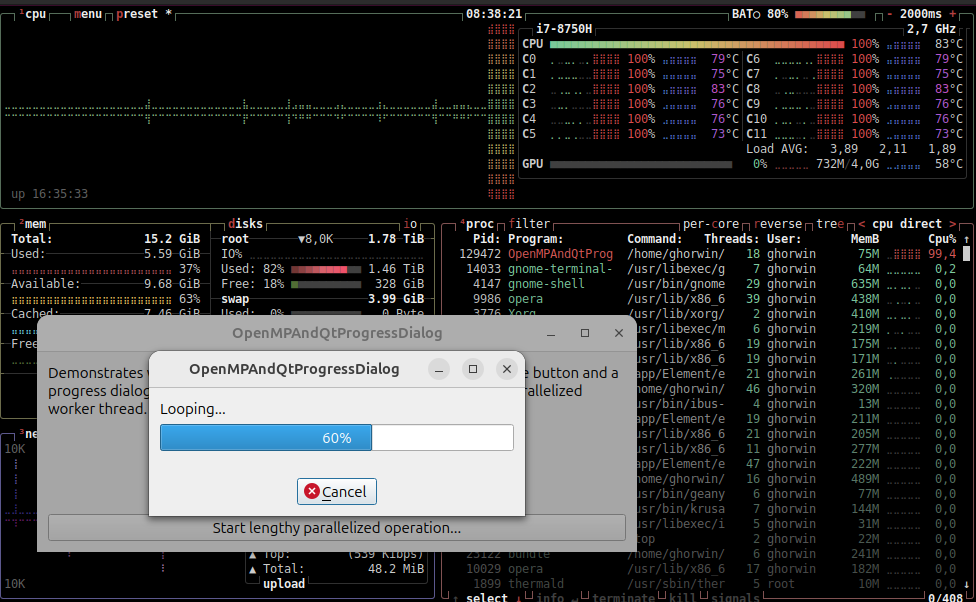
Vorzeitiger Schleifenabbruch
Wenn man im GUI-Progressdialog auf Cancel drückt, so wird die Membervariable m_abort im Workerthread auf true gesetzt.
In seriellem Code würde man einfach schreiben:
1
2
3
4
5
for (int i=0; i<maxCycles; ++i) {
// ...
if (m_abort)
break;
}
Nun kann man in OpenMP-parallelisiertem Code nicht einfach ein break verwenden. Die sinnvollste Variante ist, dass jeder der Threads einfach vorspult, wenn das Flag gesetzt ist:
1
2
3
4
5
for (int i=0; i<maxCycles; ++i) {
if (m_abort)
continue; // fast-forward to end of chunk
// ...
}
Natürlich werden dennoch alle Chunks durchlaufen. Ein Thread, der mit seinem Chunk fertig ist, holt sich sofort den nächsten, nur um den auch wieder schnell vorzuspulen. Trotzdem geht das rasant schnell.
Das war’s. Den kompletten Beispiel-Quelltext hab ich oben verlinkt.