Performance Optimierung mit Valgrind/Callgrind und KCachegrind
Einleitung/Hintergrund
Effizienten Quelltext in C++ zu schreiben, sodass Programme mit geringem Speicherverbrauch und so schnell wie möglich laufen, ist häufig nicht trivial. Vor allem, weil manchmal Speicherverbrauch reduzieren und Rechengeschwindigkeit steigern gegensätzliche Optimierungsziele sein können. Interessanterweise ist aber heutzutage häufig auch der Speicherzugriff und die verfügbare Bandbreite (bzw. Level 1, 2 und 3 Cachegrößen) kritisch für gute Performance.
Beim Schreiben numerischer Solver oder Algorithmen oder allgemein bei aufwändigen Berechnungen gelten aber immer noch die goldenen Regeln der Optimierung:
-
Mach Weniger (engl. Do Less Work) : wenn ich (aufwändige) Berechnungen nur einmal machen kann, mach es wirklich auch nur einmal und speichere das Ergebnis für die nächste Ausführung. Rund um diese Regel gibt es etliche spezifische Programmierparadigmen, wie z.B. Lazy evaluation oder over eager evaluation (siehe die entsprechenden Kapitel in Scott Meyers’ “Effective C++” Büchern). Die wichtigste Anwendung dieser Regel betrifft Schleifen (loop kernels): wenn ein Berechnungsergebnis nicht vom Schleifenzähler abhängt, zieh es raus aus der Schleife und vermeide so unnötige Neuberechnungen.
-
Zuerst Messen, dann Optimieren (engl. Profile first, optimize after): Statt viel Arbeitszeit darauf zu verwenden, Programmstellen auf Verdacht (“das sieht aufwändig aus”) zu optimieren, sollte man stattdessen immer erst einmal Nachmessen, welche Programmteile wirklich viel Zeit brauchen, und erst dann die kritischsten Abschnitte des Programms zuerst überarbeiten. Darum geht es in diesem Artikel.
Profiling/Messung des Arbeitsaufwands in Programmen
Es gibt grundsätzlich mehrere Methoden, den benötigten Aufwand im Programm zu messen:
Manuelle Instrumentierung
Man kann mit Timern arbeiten, und manuell den Zeitaufwand in bestimmten Bereichen des Programms messen. Dies hat kaum Auswirkungen auf die Ausführungszeit des Programms, liefert aber eben nur begrenzte Informationen über bestimmte, vorher bekannte/identifizierte Problemstellen.
Ein Beispiel dafür ist QElapsedTimer oder eine x-beliebige C++-Timerklasse, welche einen High-Precision-Timer implementiert und so auch Mikrosekunden genau messen kann.
Zur Referenz: So instrumentiert dauert die Ausführung des in diesem Artikel verwendeten Testbeispiels insgesamt 1.38 s.
Profiling vom Compiler einbauen lassen
Dazu kann man Programme mit bestimmten Compileroptionen compilieren und dann ausführen. Der zusätzliche, vom Compiler hinzugefügte Code generiert dann ein Protokoll über die benötigte Programmzeit generiert.
Beim GCC macht man dies durch hinzufügen der Compileroption -pg, eventuell zusätzlich mit der Option -a für detailliertere Informationen. Die Ausführung des Programmes dauert nur minimal länger, ca. 1.4 s.
Es wird eine Datei gmon.out erstellt. Durch Ausführung des Programms gprof kann diese Binärdatei in eine lesbare Ausgabe gewandelt werden:
1
2
3
4
# Ausführen des Programms und Generieren der gmon.out
../bin/release/solver
# verwendet die im aktuellen Arbeitsverzeichnis erstellte gmon.out
gprof ../bin/release/solver > results.txt
Die Interpretation der Ergebnisse ist im Internet vielfach dokumentiert.
Externe Funktionsprofiler
Man kann ein externes Profilingtool nutzen, welches zur Laufzeit prüft, in welchen Funktionen wie viel Zeit verbraucht wird. Dazu muss das Programm selbst nicht verändert werden, sonder kann direkt so analysiert werden, wie es kompiliert wurde. Damit man allerdings die zeitaufwändigen Funktionen dem Quelltext zuordnen kann, sollte man das Programm im Release-Modus aber unter Einbettung der Funktionssignaturen compilieren. Unter Linux (mit GCC) gelingt das z.B. unter Verwendung der Compileroption -O2 -g.
Ein so übersetztes Programm kann dann mit einem Funktionsprofiler gestartet und analysiert werden.
Nachfolgend wird der Open-Source-Profiler valgrind verwendet.
1
2
# Installation unter Ubuntu/Debian-basiertem Linux
sudo apt install valgrind
Es gibt zwei verschiedene Ausführungsvarianten:
- Prüfung der Cache-Performance, d.h. effizienter Nutzer von L2 und L3 Caches
- Prüfung des Zeitverbrauchs der Anwendung nach Funktionen (wie in den obigen Beispielen)
Der Aufruf lautet:
1
2
3
4
# Ausführen als Cache-Profiler
valgrind --tool=cachegrind ../bin/release/solver /path/to/project.prj
# Ausführen als Funktions-Profiler
valgrind --tool=callgrind ../bin/release/solver /path/to/project.prj
Beim Cache-Profiling dauert die Ausführung 1.6 min und man erhält eine Zusammenfassung in der Form:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
==21486==
==21486== I refs: 18,401,226,916
==21486== I1 misses: 1,017,157
==21486== LLi misses: 10,860
==21486== I1 miss rate: 0.01%
==21486== LLi miss rate: 0.00%
==21486==
==21486== D refs: 6,822,908,593 (4,941,290,815 rd + 1,881,617,778 wr)
==21486== D1 misses: 17,991,183 ( 13,809,004 rd + 4,182,179 wr)
==21486== LLd misses: 1,548,246 ( 261,577 rd + 1,286,669 wr)
==21486== D1 miss rate: 0.3% ( 0.3% + 0.2% )
==21486== LLd miss rate: 0.0% ( 0.0% + 0.1% )
==21486==
==21486== LL refs: 19,008,340 ( 14,826,161 rd + 4,182,179 wr)
==21486== LL misses: 1,559,106 ( 272,437 rd + 1,286,669 wr)
==21486== LL miss rate: 0.0% ( 0.0% + 0.1% )
Beim Funktionsprofiling dauert die Ausführung schon 2.07 min mit der Zusammenfassung:
1
2
3
4
5
==21197==
==21197== Events : Ir
==21197== Collected : 18364560511
==21197==
==21197== I refs: 18,364,560,511
Die Zahl zwischen den == ist immer die Prozess-ID, welche sich im Dateinamen der generierten Ergebnisdateien wiederfindet. Valgrind erstellt Dateien im Format cachegrind.out.<pid> bzw. callgrind.out.<pid>, also im Fall oben die Dateien cachegrind.out.21486 und callgrind.out.21197.
Analyse der Valgrind-Profilingdaten mit KCacheGrind
Die Open-Source-Software KCacheGrind ist ideal für die Analyse dieser Performancedaten.
1
2
# Installation unter Ubuntu/Debian-basiertem Linux
sudo apt install kcachegrind
Startet man das Programm in einem Arbeitsverzeichnis mit cachegrind/callgrind-Ausgabedateien, so öffnet KCacheGrind automatisch die jünste Datei. Falls es mehrere Dateien gibt, so öffnet KCacheGrind alle Dateien und zeigt eine Auswahl der verfügbaren Aufzeichnungen:
KCacheGrind mit mehreren CallGrind-Aufzeichnungen und Übersicht
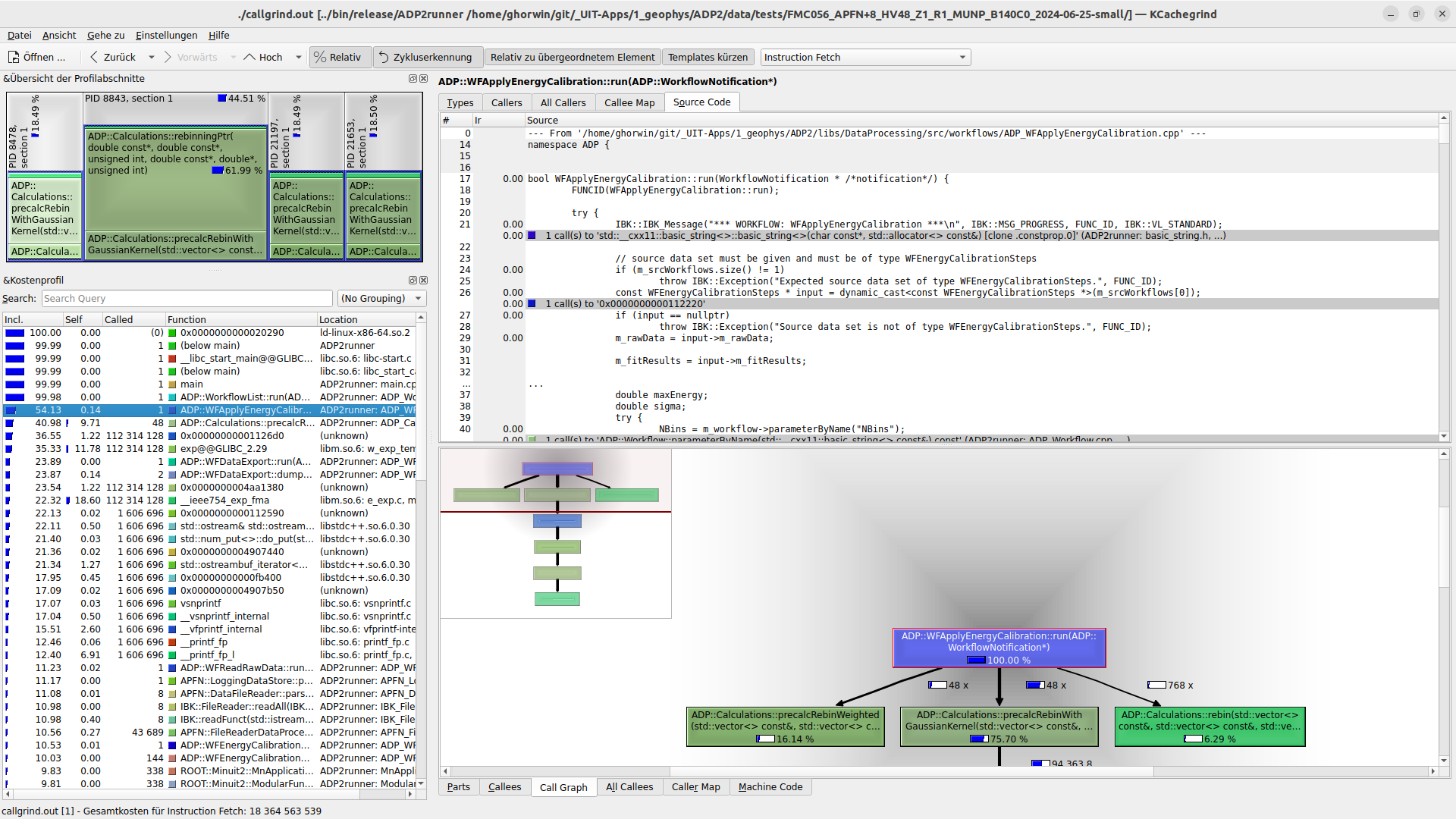
Dieses schnelle Umschalten zwischen den Aufzeichnungen erleichtert das Vergleichen verschiedener Optimierungen, siehe Abschnitt Optimierungen vergleichen.
Kritischsten Funktionen
Das Programm selbst zeigt links das “flat profile” an, also welche Funktion selbst die meiste Zeit verbraucht bzw. welche Funktion einschließlich der aufgerufenen Unterfunktionen die meiste Zeit verbringt. Dies kann in der rechten Seite des Programms auch gut in der Baumdarstellung visualisiert werden:
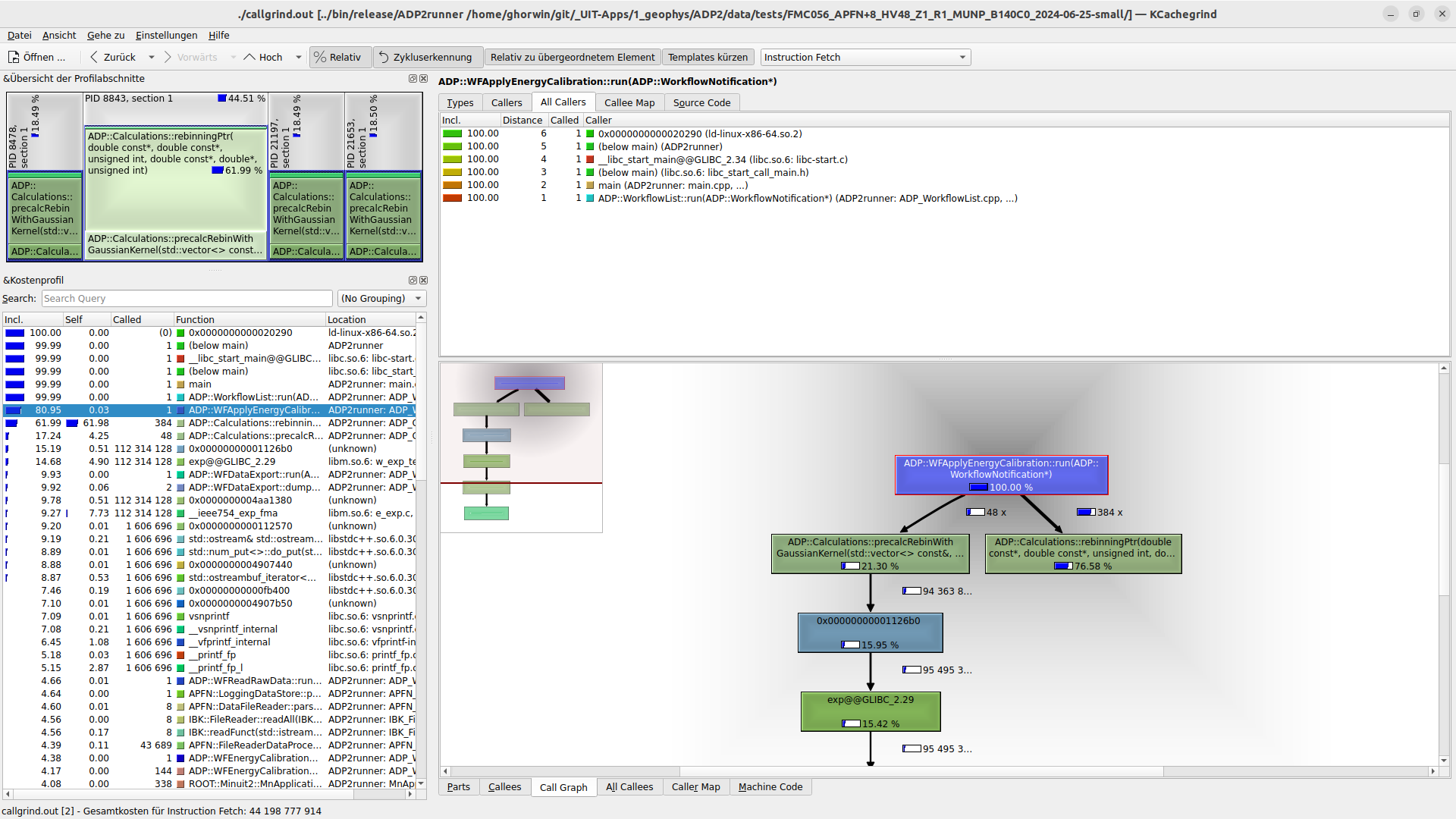
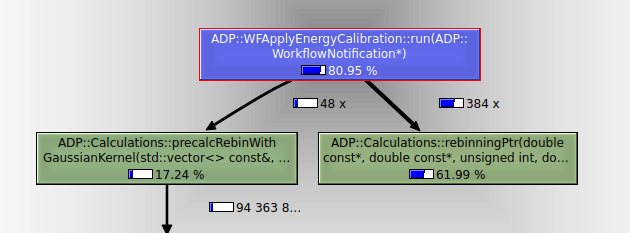
Im oben gezeigten Beispiel verbraucht die Funktion ADP::WFApplyEnergyCalibration::run(ADP::WorkflowNotification*) ca. 80% der gesamten Ausführungszeit. Wenn man diese wie im Screenshot oben auswählt, wird auf der rechten Seite angezeigt, welche Unterfunktionen prozentual die meiste Zeit verbrauchen. Hier ist das ADP::Calculations::rebinningPtr(...).
Ausführungsvarianten vergleichen und Optimierungsansätze bewerten
Nun geht es an die Optimierung. Ist eine Funktion mit signifikantem Bearbeitungsaufwand gefunden, kann man diese nun überarbeiten und hoffentlich eine Bescheunigung erzielen. Nachdem man das Programm neu gebaut und erneut durch valgrind gescheucht hat, kann man nun prüfen, ob und wie viel die Optimierung gebracht hat. Dabei gibt es aber einiges zu beachten.
Vergleichbare Messwerte erhalten
Beim Profilen von Software kann es manchmal passieren, dass die Ausführung langsamer ist als bei früheren Messerungen (thermisches Throttling, andere, rechenintensive Prozesse,…). Daher sollte man zunächst kurz mal prüfen, ob man auch vergleichbare Daten erhalten hat.
Standardmäßig zeigt KCacheGrind relative Aufwandszahlen an. Wenn man nun verschiedenen Programmvarianten vergleichen will, so sollte man im Menü auf “Absolut” umstellen und sich dann eine nicht veränderte Funktion suchen.
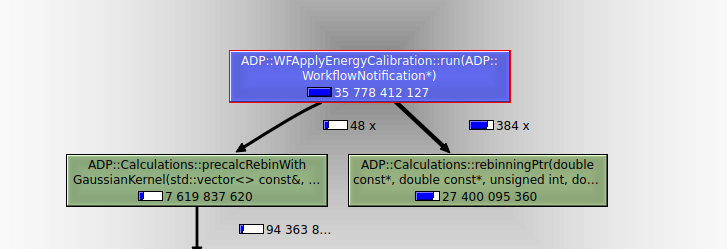
Vor der Optimierung - Absolute Kosten
Nach der Optimierung - Absolute Kosten
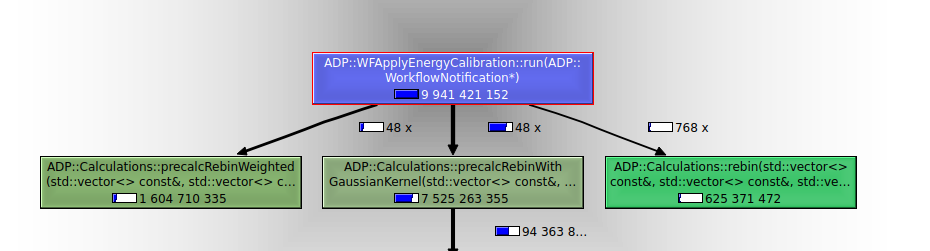
In diesem Beispiel wurde die Funktion ADP::Calculations::precalcRebinWidthGaussianKernel nicht verändert. Die Funktion wurde gleich oft aufgerufen (48x), und die Gesamtzeit war ähnlich (7619xxxxxx Ticks vs. 7525xxxxxx Ticks). Die Messwerte sind also vergleichbar.
Optimierte Funktion vergleichen
Nun kann man sich die Verteilung des Aufwands anschauen, am Besten durch Auswahl einer darüberliegenden Funktion, hier ADP::WFApplyEnergyCalibration::run:
Vor der Optimierung - Relative Kosten
Nach der Optimierung - Relative Kosten
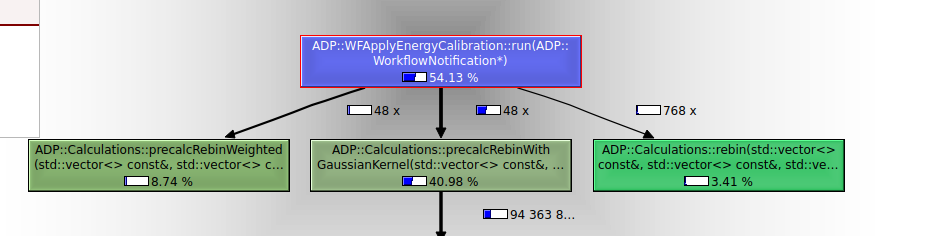
Die Funktion hatte vorab noch 80% der gesamten Laufzeit benötigt und braucht nun nur noch 54% - schon eine deutliche Verbesserung. Der Teil der Funktion, welcher vorab noch 66% der Rechenzeit gebraucht wurde, ist auf 8,7%+3,4%=12,1% geschrumpft.
Nun ist es die andere Funktion (vorab nur ca. 17% der Laufzeit), welche mit ca. 41% den größten Aufwand verursacht und die nun als nächstes optimiert werden sollte.
Die tatsächliche Beschleunigung einer einzelnen Funktion oder einen Quelltextteils durch Optimierung lässt sie aus diesen relativen Zahlen nicht ableiten. Man kann dazu aber wieder die absoluten Zahlen oben nehmen und sich wieder eine unveränderte Funktion als Bezugspunkt wählen. Hat vor der Optimierung die Funktion
ADP::Calculations::rebinningPtr(...)noch das 27400/7619 = 3,6-fache gebraucht, so ist es nach der Optimierung nur noch das (1604 + 625)/7525 = 0,3-fache. Das entspricht also einer Geschwindigkeitsbeschleunigung von Faktor 3,6/0,3 = 12. Immerhin!
Dokumentation der Optimierungen
Abschließend noch ein Tip für die Performanceoptimierung von Rechenkernen. Da bestimmte Optimierungen sich mitunter nur bei konkreten Simulationskonfigurationen auswirken, lohnt es sich den Erfolg von verschiedenen Optimierungen detailliert zu dokumentieren. Typischerweise packt man irgendwann später (1 Jahr oder so, wenn man sich an die Details der Optimierung nicht mehr erinnert) wieder einmal den Profiler aus, um herauszufinden, was plötzlich so lange dauert. Und dann ist eine Liste von Optimierungsversuchen und deren Erfolg oder “bringt nichts”-Erkenntnisse schon ganz nützlich, um nicht umsonst die gleichen Optimierungen erneut (erfolglos) zu versuchen.