Icosphere (Ikosaeder-Kugel oder geodätische Kugel) in OpenGL
Geometrien/Meshes für Kugeln
In 3D Szene braucht man immer mal Kugeln. Diese approximiert man typischerweise durch Dreiecke oder Vierecke. Am Einfachsten ist wohl die Verwendung eines Zylinder-Meshes, wobei man die Koordinaten an den Polstellen der Kugeln zusammenzieht. Wichtig ist hierbei, dass alle Dreiecke an den Polstellen die gleiche Polstellenkoordinate und den gleichen Normalenvektor verwenden, sonst sieht das seltsam aus :-)
Icosphere-Mesh
Aber viel besser ist eigentlich der Ansatz, mit einem Ikosaeder anzufangen. Der besteht ja aus 20 gleichseitigen (und damit auch gleichgroßen Dreiecken). Eine Kugel wird dadurch aber nur recht grob angenähert.
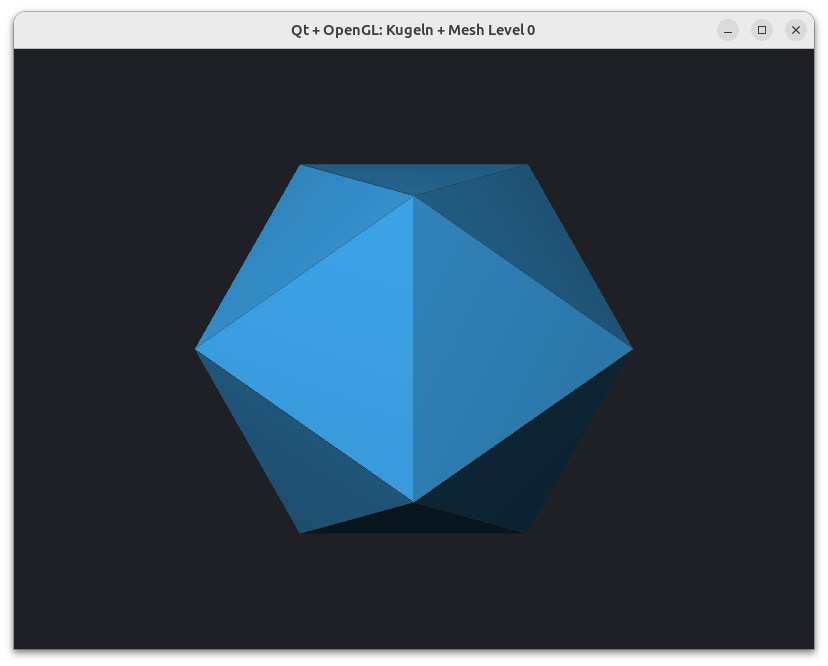
Die Idee ist jetzt, jedes Dreieck in 4 ebenfalls gleichseitige Dreiecke zu zerlegen und damit die Kugel anzunähern. Dieses Verfahren kann man dann iterativ wiederholen und erhält so Kugelapproximationen unterschiedlicher Detailstufe.
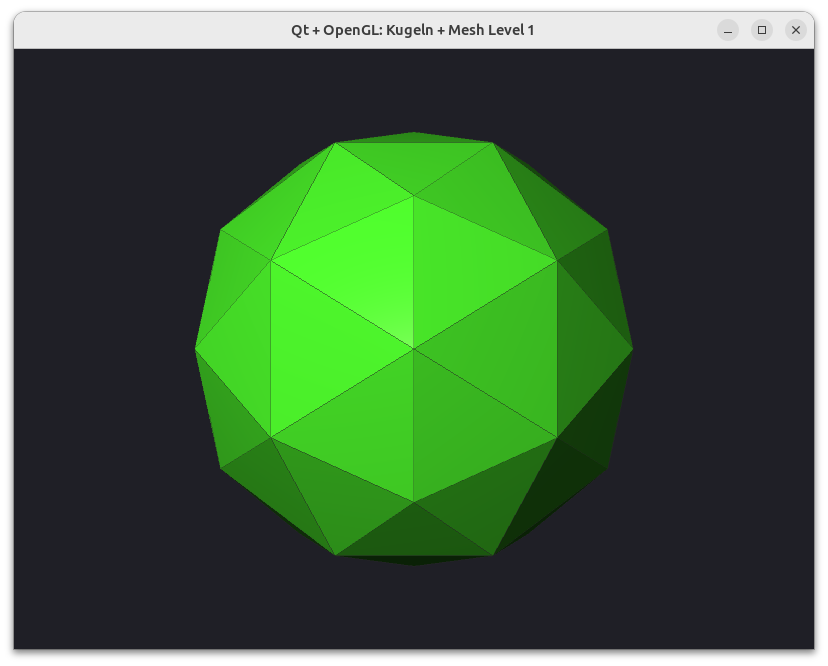
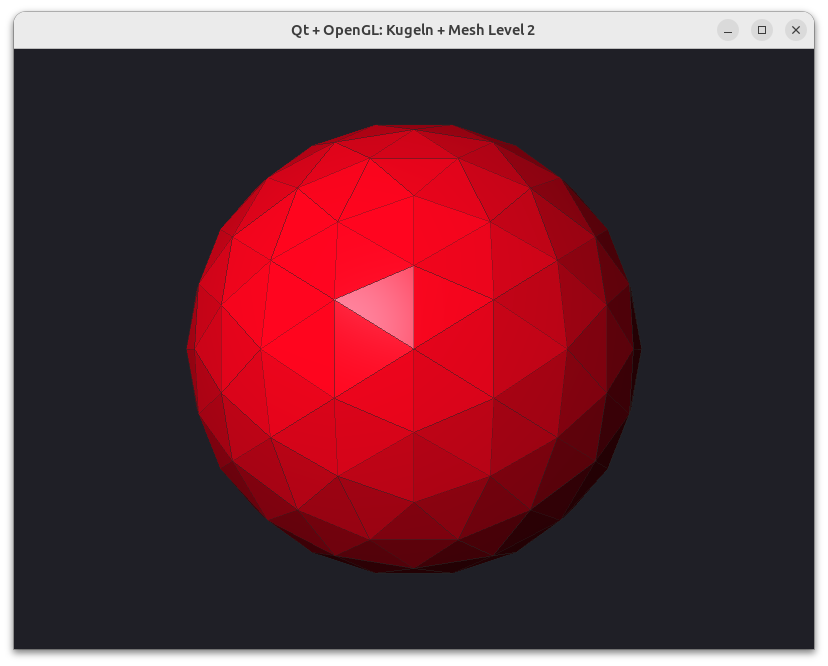
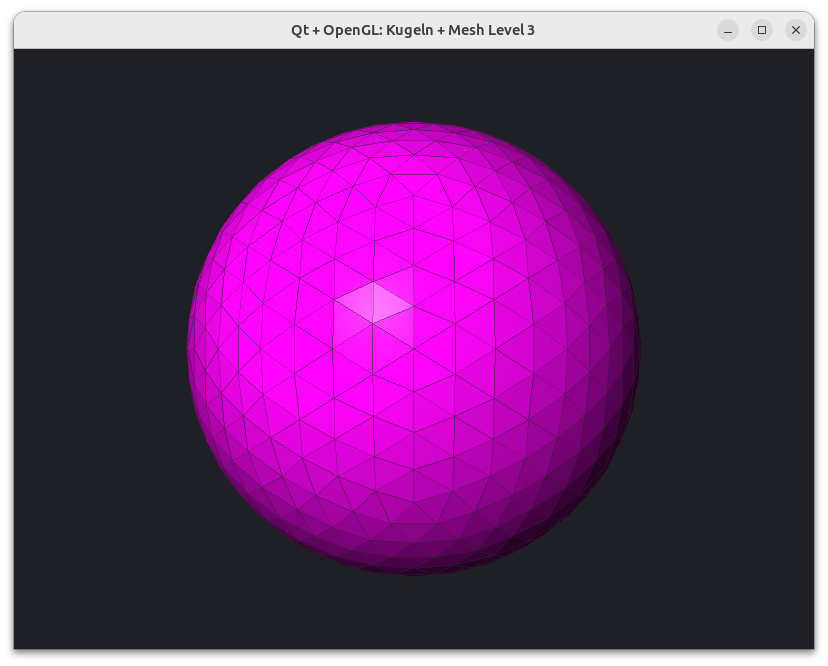
Implementierung
Das ganze nachfolgende Programm basiert auf dem minimalistischen Rotating Cube Beispiel: OpenGLRotatingCube-Example.7z. Es lohnt sich vielleicht, dieses Beispiel zunächst anzusehen.
Um so eine Icosphere in OpenGL zu rendern, benötigt man die Geometrie, d.h. die Vertexkoordinaten und die Indexe der zu zeichnenden Dreiecke. Um später mal unterschiedlich große Kugeln generieren zu können, erstellt man zunächst eine Ikosaeder-Geometry mit Einheitsradius. Der folgende Quelltext zeigt die Erstellung eines Icosphere-Gitters.
Header-Datei SphereMesh.h:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#pragma once
#include <QColor>
#include <QVector3D>
#include <QtGui/QOpenGLFunctions>
#include "Vertex.h"
/*! A triangulated unit sphere mesh built from a subdivided icosahedron (icosphere).
All triangles are of near-uniform size, avoiding the pole-distortion of UV spheres.
Per-vertex normals equal the normalized vertex positions (smooth shading).
Usage: construct with center/radius/color, then call copy2Buffer()
to fill caller-provided vertex and element buffers.
*/
class SphereMesh {
public:
SphereMesh(const QVector3D ¢er, float radius, QColor color = Qt::blue);
void setColor(QColor c) { m_color = c; }
void copy2Buffer(VertexVNC *&vertexBuffer,
GLuint *&elementBuffer,
unsigned int &elementStartIndex) const;
static void setSubdivisionLevel(unsigned int level) {
SubdivisionLevel = level;
VertexCount = 10 * unsigned(std::pow(4, level)) + 2;
IndexCount = 3 * 20 * unsigned(std::pow(4, level));
}
static unsigned int SubdivisionLevel;
static unsigned int VertexCount;
static unsigned int IndexCount;
private:
QVector3D m_center;
float m_radius;
QColor m_color;
};
Implementierungs-Datei SphereMesh.cpp:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
#include "SphereMesh.h"
#include <array>
#include <cmath>
#include <map>
static std::vector<QVector3D> s_unitNormals;
static std::vector<GLuint> s_faceIndices;
// Icosphere with 3 subdivisions of the base icosahedron (20 triangles):
// VertexCount = 10 * 4^3 + 2 = 642
// IndexCount = 3 * 20 * 4^3 = 3840 (3 indices per triangle, 1280 triangles)
unsigned int SphereMesh::SubdivisionLevel = 3;
unsigned int SphereMesh::VertexCount = 642;
unsigned int SphereMesh::IndexCount = 3840;
// *** Static Functions ***
static GLuint midpoint(std::vector<QVector3D> &verts,
std::map<std::pair<GLuint, GLuint>, GLuint> &cache,
GLuint i1, GLuint i2)
{
GLuint lo = std::min(i1, i2);
GLuint hi = std::max(i1, i2);
auto key = std::make_pair(lo, hi);
auto it = cache.find(key);
if (it != cache.end())
return it->second;
QVector3D mid = (verts[i1] + verts[i2]) * 0.5f;
mid.normalize();
GLuint idx = static_cast<GLuint>(verts.size());
verts.push_back(mid);
cache[key] = idx;
return idx;
}
static void ensureUnitSphere() {
if (!s_unitNormals.empty())
return;
const float t = (1.0f + std::sqrt(5.0f)) / 2.0f; // golden ratio
std::vector<QVector3D> verts;
verts.reserve(SphereMesh::VertexCount);
auto addV = [&](float x, float y, float z) {
QVector3D v(x, y, z);
v.normalize();
verts.push_back(v);
};
addV(-1, t, 0); // 0
addV( 1, t, 0); // 1
addV(-1, -t, 0); // 2
addV( 1, -t, 0); // 3
addV( 0, -1, t); // 4
addV( 0, 1, t); // 5
addV( 0, -1, -t); // 6
addV( 0, 1, -t); // 7
addV( t, 0, -1); // 8
addV( t, 0, 1); // 9
addV(-t, 0, -1); // 10
addV(-t, 0, 1); // 11
using Face = std::array<GLuint, 3>;
std::vector<Face> faces = {
// 5 faces around the top vertex (0)
{0,11, 5}, {0, 5, 1}, {0, 1, 7}, {0, 7,10}, {0,10,11},
// 5 faces adjacent to the top band
{1, 5, 9}, {5,11, 4}, {11,10, 2}, {10, 7, 6}, {7, 1, 8},
// 5 faces around the bottom vertex (3)
{3, 9, 4}, {3, 4, 2}, {3, 2, 6}, {3, 6, 8}, {3, 8, 9},
// 5 faces adjacent to the bottom band
{4, 9, 5}, {2, 4,11}, {6, 2,10}, {8, 6, 7}, {9, 8, 1}
};
for (unsigned int level = 0; level < SphereMesh::SubdivisionLevel; ++level) {
std::map<std::pair<GLuint, GLuint>, GLuint> midCache;
std::vector<Face> newFaces;
newFaces.reserve(faces.size() * 4);
for (const Face &f : faces) {
GLuint m01 = midpoint(verts, midCache, f[0], f[1]);
GLuint m12 = midpoint(verts, midCache, f[1], f[2]);
GLuint m20 = midpoint(verts, midCache, f[2], f[0]);
newFaces.push_back({f[0], m01, m20});
newFaces.push_back({f[1], m12, m01});
newFaces.push_back({f[2], m20, m12});
newFaces.push_back({m01, m12, m20});
}
faces = std::move(newFaces);
}
Q_ASSERT(verts.size() == SphereMesh::VertexCount);
Q_ASSERT(faces.size() == SphereMesh::IndexCount / 3);
s_unitNormals = std::move(verts);
s_faceIndices.reserve(SphereMesh::IndexCount);
for (const Face &f : faces) {
s_faceIndices.push_back(f[0]);
s_faceIndices.push_back(f[1]);
s_faceIndices.push_back(f[2]);
}
}
// *** SphereMesh implementation ***
SphereMesh::SphereMesh(const QVector3D ¢er, float radius, QColor color)
: m_center(center)
, m_radius(radius)
, m_color(color)
{
ensureUnitSphere();
}
void SphereMesh::copy2Buffer(VertexVNC *&vertexBuffer,
GLuint *&elementBuffer,
unsigned int &elementStartIndex) const
{
for (unsigned int i = 0; i < VertexCount; ++i) {
QVector3D pos = m_center + m_radius * s_unitNormals[i];
vertexBuffer[i] = VertexVNC(pos, s_unitNormals[i], m_color);
}
vertexBuffer += VertexCount;
for (unsigned int i = 0; i < IndexCount; ++i)
elementBuffer[i] = elementStartIndex + s_faceIndices[i];
elementBuffer += IndexCount;
elementStartIndex += VertexCount;
}
Im Konstruktor der Klasse SphereMesh wird zunächst die statische Funktion ensureUnitSphere() aufgerufen, die die normalisierten VNC-Vertexe und Indexe generiert. Das eigentliche Skalieren der Kugeln und verschieben in den gewünschten Mittelpunkt erfolgt in copy2Buffer(). Bei Animation der Sphere (Bewegung, Farbänderung) setzt man einfach die Membervariablen m_center, m_radius oder m_color und ruft erneut copy2Buffer() auf.
Diese Funktion kopiert alle Vertexes und alle Indexes in zwei (sehr) große Speicherblöcke, die dann auf die Grafikkarte geschoben werden. Dadurch können alle Kugeln und deren Dreiecke mit einem einzelnen Render-Call gezeichnet werden. Das geht ziemlich schnell, braucht aber eben auf der Grafikkarte auch ziemlich viel Speicher (wenn die Anzahl der Kugeln steigt, siehe Tabelle unten).
Dadurch, dass sich alle Kugeln die statischen, normalisierten Koordinaten in den statischen Vektoren s_unitNormals und s_faceIndices teilen, ist die Hauptspeichernutzung minimal. Es wäre ja cool, wenn man dieses Konzept auch auf der Grafikkarte selber machen könnte. Und das geht auch, siehe Abschnitt “Instanziertes Rendern” weiter unten.
Die Generierung der Einheitskugel
Die Funktion ensureUnitSphere() definiert zunächst alle 12 Ecken des Ikosaeders (woher die Berechnung stammt, kann man u.A. im Artikel Der Ikosaeder auf https://www.walter-fendt.de/math nachlesen). Dadurch, dass eine Einheitsikosaeder um den Koordinatenursprung definiert wird, sind Eckkoordinaten und Normalenvektoren identisch.
Dann werden die 20 Dreieicke in der Indexliste definiert. Das zusammen ergibt den Ikosaeder bzw. Kugelapproximation der Stufe 0. Danach werden die Dreiecke iterativ verfeinert. Die Anzahl der Iterationsstufen (Level) wird zusammen mit der Gesamtzahl der Vertexe und Indexe ebenfalls in statischen Variablen gehalten.
Die Verfeinerung ist hinreichend trivial: jede Kante eines Dreickes wird halbiert und die Koordinate bzw. die Normalenvektoren am Mittelpunkt durch Mitteln berechnet und anschließend normalisiert (sonst wäre es ja nur die Mitte auf der Sekante). Da jede Kante Teil von 2 Dreiecke ist, werden die so berechneten neuen Koordinaten in einem Cache gemerkt, um Doppelberechnung zu vermeiden (der Key der Map ist das Paar der gerade betrachteten Ecken-Indexe).
Zum Ende der Funktion werden Vertexdaten und Indexe in die linearen Speicherbereiche kopiert (die Strukture Face wird “verflacht” in eine einfache Liste aufeinanderfolgender Indexe).
Die Implementierung ist als komplettes Beispiel herunterladbar:
Rendern mit Phong-Shader
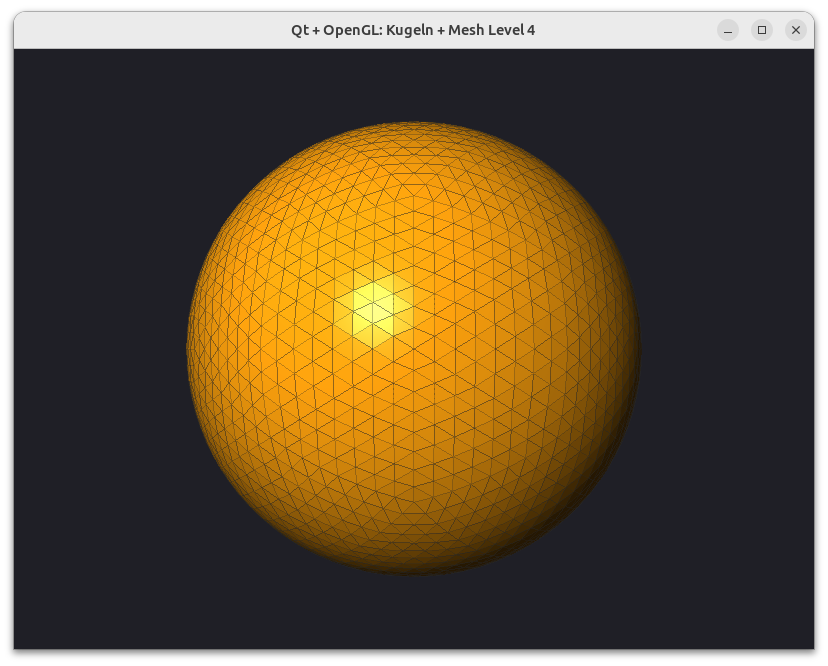
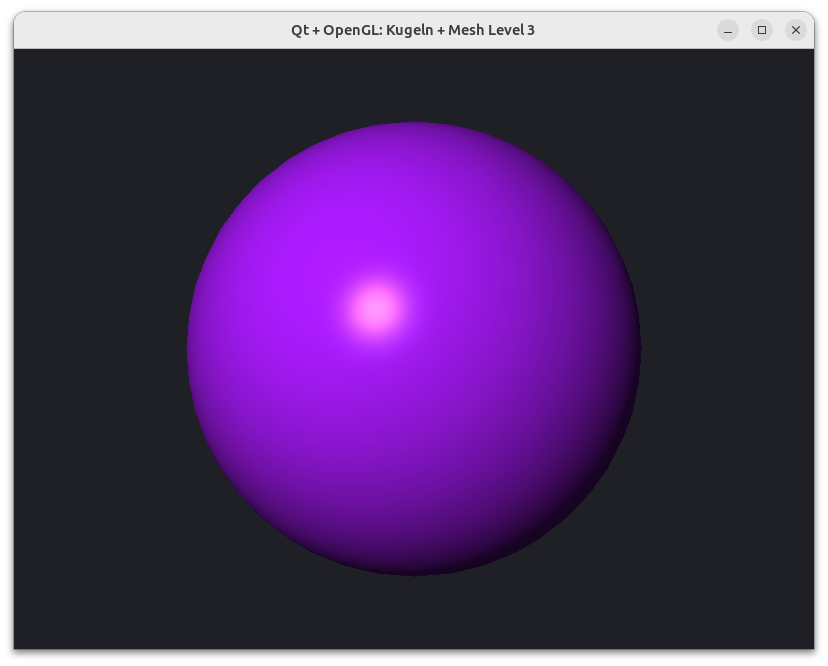
Wenn man nun eine so generierte Kugel mit einem Phong-Shader rendert, sieht das bereits bei niedrigen Verfeinerungsstufen sehr gut aus.
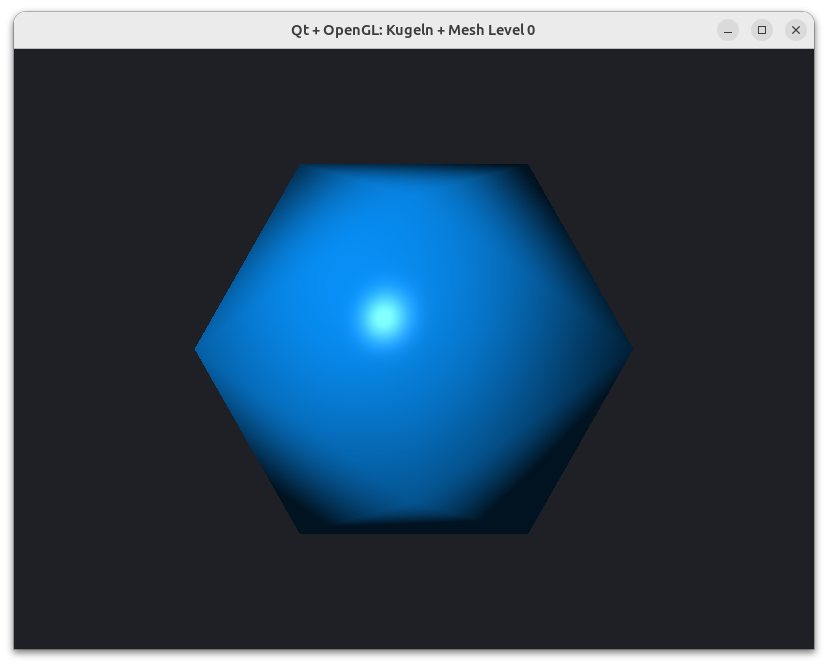
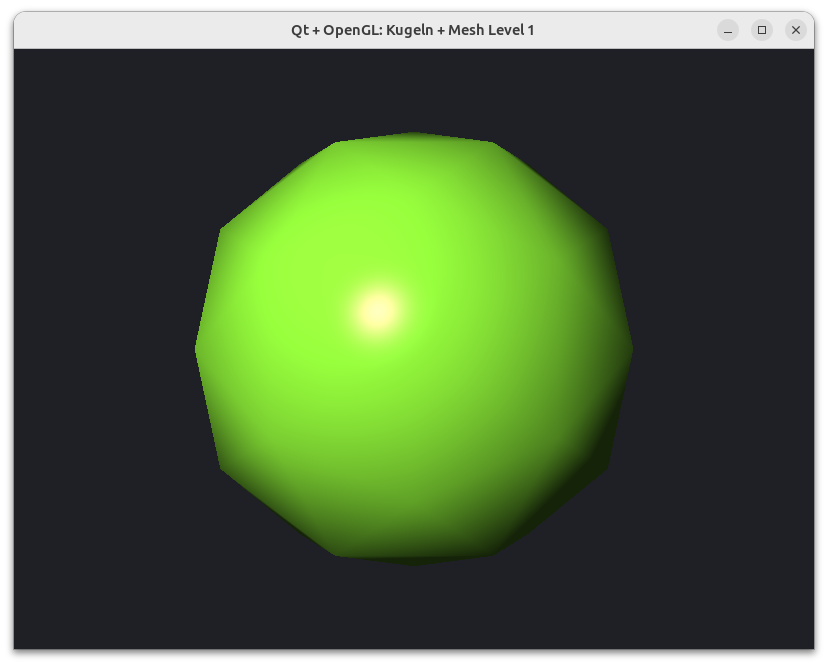
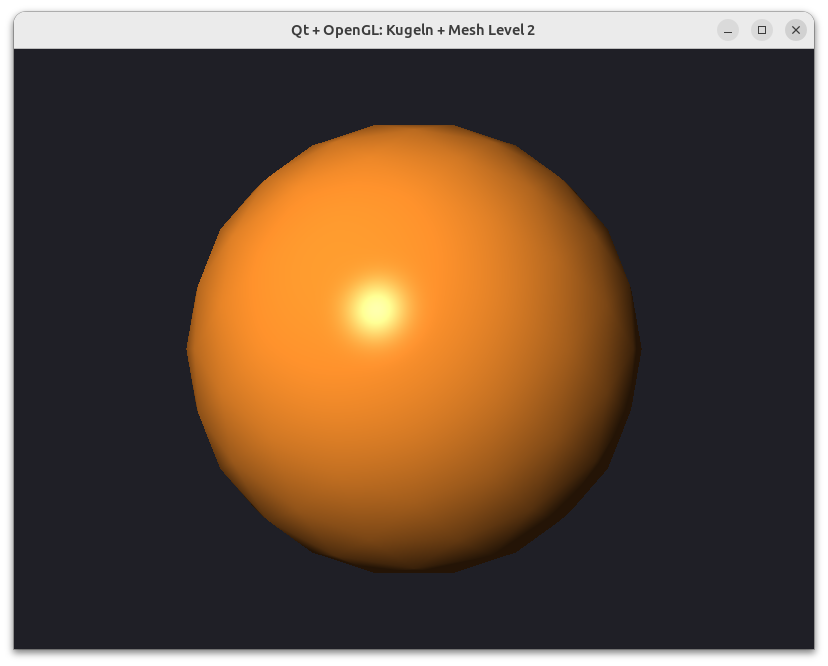
Geschwindigkeits- und GPU-Speicheroptimierung
Wenn man jetzt viele Kugeln hat, bedeutet dies (ab einem höheren Verfeinerungsgrad, wie z.B. Iterationsstufe 3) einen schon nicht unerheblichen Speicherbedarf. Auf der CPU wird das durch die Einheitskugel minimiert, aber im Grafikspeicher werden die Vertexe und Indexe aller Kugeln gehalten. Wenn man diese auch noch animiert (bewegt), muss man diesen VBO/EBO Puffer auch in jedem Frame auf die Grafikkarte kopieren. Und das dauert, auch wenn das eigentliche Rendern später schnell geht.
Der Speicherbedarf für die Vertex/Index-Puffer steigt exponentiell mit jeder Verfeinerungsstufe:
1
2
VertexCount = 10 * 4^Level + 2
IndexCount = 3 * 20 * 4^Level // 3 indices per triangle
- Speicherbedarf für einen Vertex:
sizeof(VertexVNC)= 9 Floats × 4 Byte = 36 Byte (Position, Normale, Farbe je alsvec3). - Speicherbedarf für einen Index:
sizeof(GLuint)= 4 Byte
Hier mal ein Vergleich der resultierenden Vertexe und Indexe und des benötigten Speichers in Abhängigkeit von der Verfeinerungsstufe.
| Level | Triangles | VertexCount | IndexCount | Memory [kB] |
|---|---|---|---|---|
| 0 | 20 | 12 | 60 | 0,7 |
| 1 | 80 | 42 | 240 | 2,4 |
| 2 | 320 | 162 | 960 | 9,4 |
| 3 | 1280 | 642 | 3840 | 37,6 |
| 4 | 5120 | 2562 | 15360 | 150,1 |
| 5 | 20480 | 10242 | 61440 | 600,1 |
Der Speicherbedarf bei Ebene 4 und 5 ist schon enorm, und das bei nur einer Kugel!
Pro Kugel mit Verfeinerungsebene 3 belegt die GPU damit:
| Puffer | Rechnung | Größe |
|---|---|---|
| VBO: 642 Vertices × 36 Byte | 642 × 36 | 22,6 KB |
| EBO: 3840 Indizes × 4 Byte | 3840 × 4 | 15,0 KB |
| Gesamt pro Kugel | 37,6 KB |
Bei N Kugeln: N × 37,6 KB.
Die Alternative: Instanced Rendering
Bei der Generierung der Vertexe und Indexe werden im CPU-RAM ja nur Vektoren für die Einheitskugel abgelegt. Wäre es nicht auch möglich, auch auf der GPU die Geometrie der Einheitskugel nur genau einmal abzulegen und für jede Kugel nur noch die kugelspezifischen Daten (Mittelpunkt, Radius, Farbe) zu übergeben?
Ja, das geht, und genau dafür ist Instanced Rendering (glDrawElementsInstanced) gedacht. Bei diesem Ansatz werden 3 Puffer benötigt:
- VBO mit Einheitskugelvertexen
- EBO mit den Indexen der Einheitskugelflächen
- Instand-VBO mit den Kugelinstanzdaten (Mittelpunkte, Radien, Farben)
Besonderheit von SphereMesh: Normale = Position
Bei der Icosphere mit glatten Normalen gilt für jeden Vertex der Einheitskugel: Normale = Einheitsposition
Die Weltposition ergibt sich im Shader zu center + radius * aUnitPos, und gleichzeitig ist aUnitPos die korrekte glatte Normale – ohne jeden Mehraufwand. Es genügt daher, einen einzigen vec3 pro Vertex zu speichern. Das spart noch mehr Speicher.
Pufferstruktur
Gemeinsamer VBO (einmalig, kugelunabhängig): 3 Float = 12 Byte (auch die einheitliche Farbe der Kugel kommt nicht mehr in die Vertex-Struktur hinein):
- 642 Vertices × 12 Byte (
vec3Einheitsposition) = 7,5 KB
Gemeinsamer EBO (einmalig):
- 3840 Indizes × 4 Byte = 15,0 KB
Instanz-VBO (N Einträge):
- N × (Mittelpunkt
vec3+ Radiusfloat+ Farbevec3) = N × 28 Byte
Speichervergleich
Hier ist mal ein Speichervergleich bei Verwendung von Kugelmeshes mit Verfeinerungsebene 3:
| N Kugeln | Aktuell | Instanced |
|---|---|---|
| 1 | 37,6 KB | 22,5 KB + 28 B ≈ 22,5 KB |
| 10 | 376 KB | 22,5 KB + 280 B ≈ 22,8 KB |
| 100 | 3,76 MB | 22,5 KB + 2,8 KB ≈ 25,3 KB |
| 1000 | 37,6 MB | 22,5 KB + 28 KB ≈ 50,5 KB |
Vertex-Shader
Im Vertexshader muss man nun die Berechnung der Kugelkoordinaten durchführen. Der Shader bekommt dafür insgesamt 4 Attributvektoren zugewiesen.
Der Trick besteht nun darin, dass der Shader alle vec3 im Attributarray aUnitPos parallelisiert bearbeitet, dabei aber jeweils pro Instanz immer die gleichen Variablen iCenter, iRadius und iColor verwendet.
1
2
3
4
5
6
7
8
9
10
11
12
13
// Pro Vertex (gemeinsamer VBO)
layout(location = 0) in vec3 aUnitPos; // Einheitsposition = glatte Normale
// Pro Instanz (Divisor = 1)
layout(location = 1) in vec3 iCenter;
layout(location = 2) in float iRadius;
layout(location = 3) in vec3 iColor;
void main() {
gl_Position = mvp * vec4(iCenter + iRadius * aUnitPos, 1.0);
vNormal = aUnitPos; // Einheitsposition ist gleichzeitig die Normale
vColor = iColor;
}
Konfiguration der Shader-Attribute
Die VBO und EBO für die Einheitskugelvertexe und Indexe werden genauso angelegt, wie vorher bei der Variante mit den großen Arrays (und allen Knotendaten/Indexen).
Beim Anlegen der Instanz-VBO gibt es eine Besonderheit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// --- Per-instance VBO (locations 1–3) -------------------------------------
m_instanceVbo.create();
m_instanceVbo.bind();
m_instanceVbo.setUsagePattern(QOpenGLBuffer::StaticDraw);
m_instanceVbo.allocate(m_instanceData.data(),
int(m_instanceData.size() * sizeof(SphereMeshInstanced::InstanceData)));
const int stride = int(sizeof(SphereMeshInstanced::InstanceData));
program.enableAttributeArray(1);
program.setAttributeBuffer(1, GL_FLOAT, 0, 3, stride); // iCenter (vec3, offset 0)
program.enableAttributeArray(2);
program.setAttributeBuffer(2, GL_FLOAT, 12, 1, stride); // iRadius (float, offset 12)
program.enableAttributeArray(3);
program.setAttributeBuffer(3, GL_FLOAT, 16, 3, stride); // iColor (vec3, offset 16)
// Mark locations 1–3 as per-instance (advance once per instance, not per vertex)
glVertexAttribDivisor(1, 1);
glVertexAttribDivisor(2, 1);
glVertexAttribDivisor(3, 1);
Die Daten für die individuellen Kugeln liegen in einem kontinuierlichen Speicherbereich m_instanceData und werden klassisch über stride und offset den Attributpuffern zugeordnet.
Dann aber wird mit dem Aufruf von glVertexAttribDivisor() festgelegt, dass diese Element einmal pro Instanz und nicht pro Vertex hochgezählt werden.
Rendern
Damit die Grafikkarte weiß, dass jetzt mittels Instanzen gerendert wird, verwendet man eine leicht andere Syntax:
1
2
3
4
5
6
7
8
9
10
11
12
m_vao.bind();
// Statt:
// glDrawElements(GL_TRIANGLES,
// GLsizei(m_elementBufferData.size()),
// GL_UNSIGNED_INT,
// nullptr);
glDrawElementsInstanced(GL_TRIANGLES,
GLsizei(SphereMeshInstanced::IndexCount),
GL_UNSIGNED_INT,
nullptr,
GLsizei(m_sphereCount));
m_vao.release();
Wäre das durch den Mehraufwand im Shader nicht langsamer?
Der Shader muss ja jetzt mehr machen. Bleibt die Frage: wäre das jetzt langsamer, als das einfache Durchschieben der Vertexdaten aus einem großen zusammengebackenen Speicherblock?
Nein – wahrscheinlich gleich schnell, bei mehr Kugeln tendenziell etwas schneller.
- Die Anzahl der Draw Calls bleibt gleich: statt
glDrawElementseinglDrawElementsInstanced. - Der Shader-Mehraufwand ist eine einzige MAD-Operation pro Vertex (
iCenter + iRadius * aUnitPos) – auf jeder modernen GPU vernachlässigbar. - Das Cache-Verhalten verbessert sich: Ein gemeinsamer VBO von 7,5 KB lässt sich dauerhaft im GPU-L1/L2-Cache halten. Je mehr Kugeln gerendert werden, desto größer der Vorteil gegenüber einem linear wachsenden gepackten Puffer.
- Bei animierten Kugeln (Bewegung, Radiusänderung) ist der Vorteil dramatisch: statt N × 37,3 KB Vertexdaten neu hochzuladen, genügen N × 28 Byte im Instanz-VBO.
Benchmarkbeispiel
Um das Ganze zu testen und zu messen, hab ich mal ein kleines Beispiel gebaut. Wir simulieren ein 3D Bällebad, in dem 4000 Kugeln einfach nur auf und ab hüpfen (ohne Kollision untereinander).
Wir vergleichen die Performance der klassischen “gebackenen” (engl. backed) Vertex-/Elementpuffer gegenüber des instanzierten Renderns. Bei der ersten Variante Nur Kamera bewegen erfolgt kein Update the GPU Speichers. Beim zweiten Mal wird der Vertexpuffer bzw. der Instanzpuffer kopiert.
| Test | Backed | Instanced |
|---|---|---|
| Nur Kamera bewegen | GPU: 3.695 ms/frame (270.6 FPS) | GPU: 3.657 ms/frame (273.4 FPS) |
| Bälle hüpfen | GPU: 16.226 ms/frame (61.6 FPS) | GPU: 3.703 ms/frame (270.0 FPS) |
Ergebnis ist eindeutig - die Zeit zum Kopieren der Daten aus dem Hauptspeicher in den GPU Speicher dominiert hier alles.
Die Implementierung ist als komplettes Beispiel herunterladbar:
Durch Ändern des Defines #define USE_INSTANCED_RENDERING in SphereObject.h kann man zwischen den Implementierungsvarianten umschalten.